
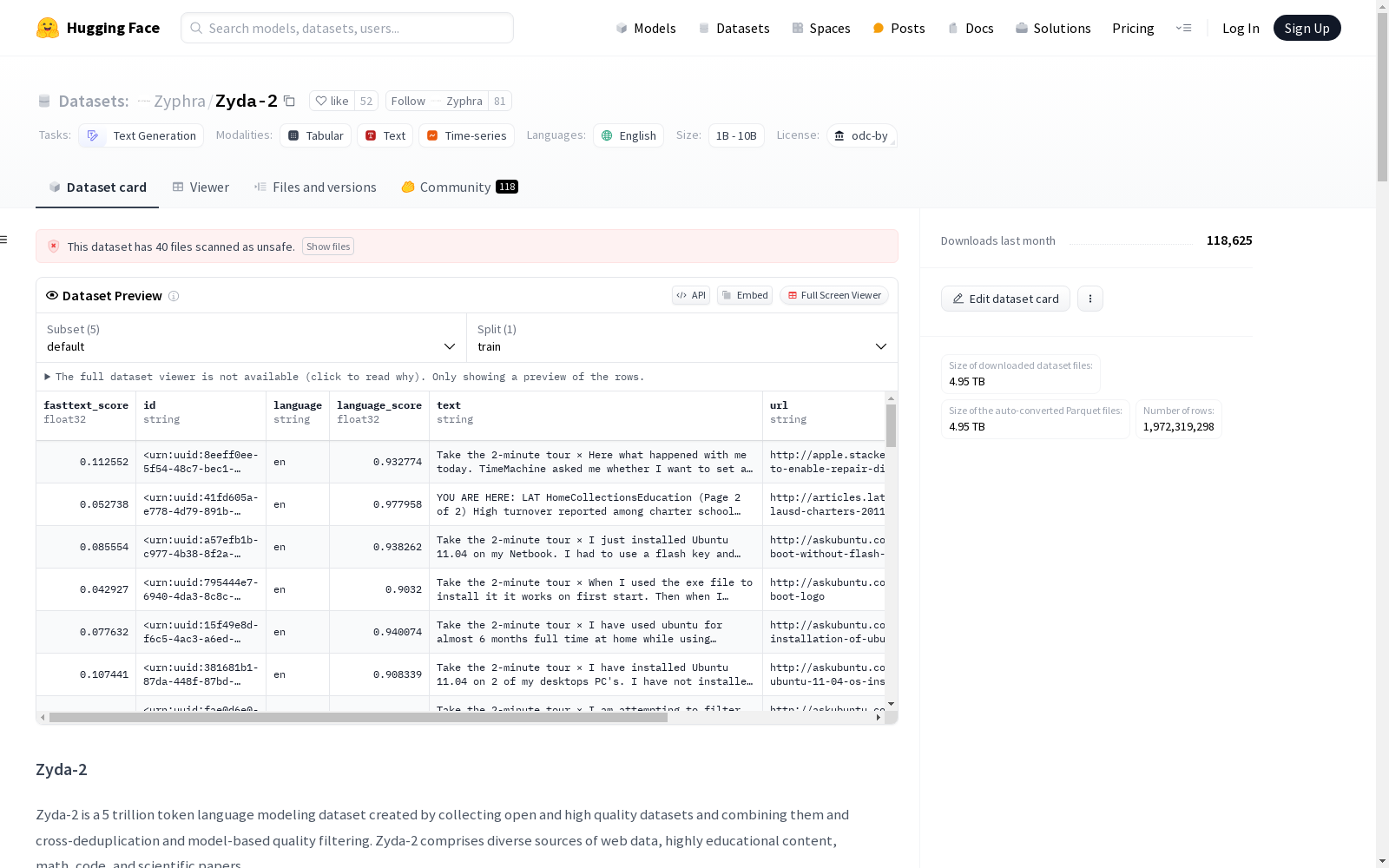
Zyphra 本次发布的数据集 Zyda-2, Zyda-2是由Zyphra机构创建的一个包含5万亿Tokens的高质量数据集,旨在用于语言模型的预训练。该数据集汇集了如FineWeb和DCLM等高质量的开源数据源,并通过交叉去重和模型质量过滤技术进一步提炼,以确保数据的高质量和多样性。创建过程中,数据集经历了严格的去重和质量筛选步骤,以提升模型的训练效果。Zyda-2主要应用于自然语言处理领域,旨在提升小规模高效模型的性能,特别是在消费者和边缘设备上的应用。
Dataset card 内容:
Files and versions 内容:
关于 arXiv , arXiv 是一个免费分发服务和开放获取的学术文章档案库,涵盖了物理学、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学以及经济学等领域。该网站上的材料并未经过 arXiv 的同行评审。